

A dialogue concerning the two chief scientific methods
A dialogue concerning the two chief scientific methods
Like, can we even run experiments?

Sim.: the pandemic has brought out the worst in our society. I cannot believe that there are so many people who are basically science deniers!
Sal.: yeah, it's terrible. But let me ask a question: what exactly is science?
Sim.: quoting Bill Nye, science is the process and the body of knowledge that enables us humans to know nature. So far, it’s the best idea we’ve ever had [1].
Sal.: perhaps it’s the best, but I wouldn’t say it’s one idea. At the very least, it’s two. Let me explain: how do you know that a new medicine is effective?
Sim.: well, you run a randomised experiment with two groups of people; to one group you give a placebo and to the other group you give the new medicine. You decide in advance that you will measure a certain outcome variable, and then compare it between the treated and the placebo group.
Amy: I must point out, Simplicio, that what you describe is merely a step in establishing scientific consensus. A scientific experiment ultimately exists at the level of description and aggregation of human behaviour and social systems. At the very least several studies of the kind you describe would be run by different groups and the results would be aggregated by a meta-analysis…
Sal.: sure, but let’s keep things simple for now. I agree that there is more to how the cake is baked than the recipe written on the box.
Amy: cool.
Sal.: anyway, to recap: randomised experiments are conducted by assigning experimental units to treatment or to control at random, with the goal of preventing selection bias [2]. They are considered the gold standard for testing the presence of a causal relation between two variables [3]. In many fields, including medicine and a range of quantitative social sciences, other kinds of evidence are often discounted as merely correlational, to the point that the motto no causation without manipulation was coined [4].
Amy: alright, the importance of manipulation is clear –these are experiments after all- but maybe it’s worth to explain why we need randomisation.
Sal.: sure. You see, usually when we run these experiments we do not fully understand the details of what is going on. We may be dealing with complex systems such as people or organisations. In the absence of randomisation, the treated and control sample may differ in subtle ways that we could not anticipate nor correct for, thus introducing a bias in the experiment’s results. I made a little drawing to make this extra clear (Fig. 1).
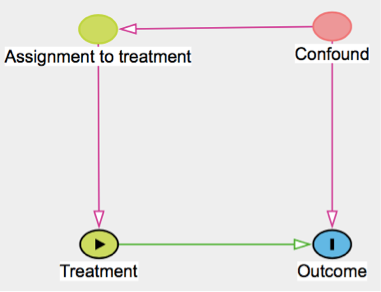
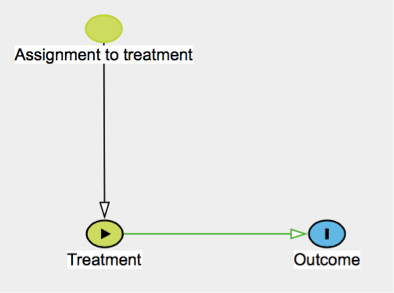
Fig. 1: Directed acyclic graph (DAG) illustrating the difference between a non-randomised experiment (top) and a randomised experiment (bottom). In the first case the causal effect of treatment on outcome is confounded by some other, potentially unobserved, variable. In the second case this risk is removed because assignment to treatment, being carried out at random, is by construction not influenced by any other variable. The DAG was drawn in dagitty [5] which is based on the approach introduced by Pearl (2009) [6].
Sim.: right.
Sal.: Now you would surely agree that randomised experiments are a pillar of the scientific method. Certainly Bill Nye would agree, too. But let me ask, how do we know that the force of gravity falls off as the distance from the source squared?
Sim.: again, we run experiments. We take a mass as the source of our gravitational field and we place a test mass at some distance from it. We measure the distance and the force acting on the test mass. Rinse and repeat. Cavendish did something along these lines to indirectly measure the density of the Earth [7].
Amy: this works in the lab, on scales of the order of a few meters. But the best constraints we have on deviations from the inverse square law are actually on the Solar system scale [8]. On those scales we cannot perform any manipulation. How can we do science just by observing planets, without running experiments?
Sal.: theory! Or, to use the words of a great statistician, various homogeneity or invariance assumptions [4]. Theory makes it possible to talk about causation in a purely observational science such as astronomy. Conversely, perceived lack of progress in certain experimental sciences has been blamed on the lack of a theoretical framework [9]. So there are at least two scientific methods.
Amy: Oh, I see what you mean. There is Method 1, which relies on a strong theoretical framework within which we predict outcomes by applying abstract manipulations to theoretical concepts. Like in Physics. The predicted outcomes are then compared to measured quantities by relying on correspondence rules between the theoretical entities and reality. My favourite historian of science –who is a physicist by the way- goes as far as to define science as Method 1 [10], even though his take is understandably controversial. Method 2 instead relies on randomised experiments to measure the effect of an intervention even in the absence of a well defined theoretical picture. It works as long as we are able to randomise the assignment to our intervention or to convince ourselves that it was naturally randomised. In Method 2, randomisation replaces the detailed theoretical knowledge of Method 1. In the last century or so, lots of progress in what can arguably also be called science -e.g. medicine- took place thanks to Method 2.
Sim.: ok, you convinced me that there are two methods. We usually conflate the two when referring to ‘the scientific method’ or ‘science’. But I think we are justified in doing so, and honestly I do not see what is your point.
Sal.: my point is that once we recognise that Method 1 and Method 2 are different tools, employed by different communities, to solve different problems, then we can try to learn something by applying one in what is usually the domain of the other. For one thing, Method 2 is conceptually simpler than Method 1 and appears easier to automate: given enough resources, it is conceivable that a simple algorithm that loops through the two steps of proposing an intervention and testing it experimentally could eventually uncover all useful interventions and the associated outcomes.
Amy: are you suggesting that we replace Method 1 with Method 2 entirely?
Sal.: Certainly not, but what if we take Method 2 seriously, insisting that a causal relation between two variables may exist only if it is possible to prove it through a randomised experiment, at least in principle? If we do this within the territory that usually belongs to Method 1, we will have a full theoretical model available. We can use that model to tell what the outcome of a randomised experiment will be. Better yet, we can use the model to predict whether running experiments is even possible to begin with.
Amy: but in the domain of Method 1, precisely because we can rely on theory, there is no fundamental problem of causal inference and randomised experiments are not relevant. I believe that you may be misunderstanding the framework of causal inference, in particular where and why it is relevant.
Sal.: would you say that recreational N2O users misunderstand how whipped cream chargers should be used because they are getting high on the gas rather than using it for whipped cream? Look, I love Method 1 and I believe it is superior to Method 2 where it is applicable. This is not the point, though. The point is whether we can understand something about Method 2 by modelling it through Method 1.
Sim.: now I am lost.
Sal.: Here is an analogy. Before special relativity, everyone expected simultaneity to be universally defined, right? This means that people assumed that for any couple of events it would always be possible to say that either one preceded the other or that they happened simultaneously. The possibility of checking that two events were simultaneous was taken for granted.
Sim.: yes, indeed.
Sal.: no one bothered to test whether it was possible to do that operationally. It seemed that you should always be able to do that because there was no obvious limit to the velocity of physical signals that you could use to synchronise clocks. What if we are in a similar situation for randomised experiments?
Sim.: what would the analogue be?
Sal.: nobody checked whether it is always possible to run an arbitrary randomised experiment to test the causal relation between any two variables. I can’t find a formal proof that it is possible to run such an experiment even in the simple context of a system governed by the usual classical mechanics equations.
Amy: well, people are running randomised experiments all the time, limited only by their resources and creativity. Why do you need a proof at all?
Sal.: people believe that they are running randomised experiments all the time, but are they? They believed they could instantaneously synchronise faraway clocks for that matter, too.
Sim.: so you are making a metaphysical point that there may be an irreducible selection bias in experimental setups. What would you do about it besides ditching empiricism altogether?
Amy.: Well, speaking for myself I would first check whether established theory –Method 1- predicts that we can make randomised experiments or not. If we could prove that it is always possible to run an arbitrary randomised controlled experiment within any mechanical system, we would already be onto something, right? It wouldn’t say much about reality, but it would at least show that Method 1 and Method 2 are consistent.
Sal.: I have bad news for you. I will show you an extremely simple mechanical system where a specific randomised experiment is impossible. Ready?
Let’s take an isolated system containing only two bodies H and L of masses MH and ML and an experimenter whose mass is assumed to be zero for simplicity. Let’s call him Josh. This is a system where we would typically apply Method 1, for instance using the laws of classical mechanics. But our experimenter Josh knows nothing of this. He just wants to know what will happen to the force FL felt by body L when he manipulates the coordinate qH of body H. We can think of qH as the treatment and FL as the outcome.
Amy: how is the coordinate qH defined?
Sal.: we can just take the line that goes from H to L as our x axis and place the origin in the center of mass. The problem is one dimensional, and we will work in the reference frame where the center of mass is at rest. Here is a nice drawing (Fig. 2) where I show body H in pink and body L in grey.
Sim.: cool, this mechanical system is simple enough that we can calculate everything we need. But what about the randomised experiment?
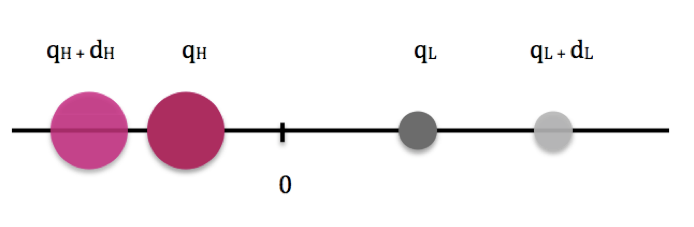
Fig. 2: Isolated, one-dimensional two-body system where the experiment of moving mass H is performed. The center-of-mass of the system coincides with the origin of the axis. In general, moving body H from its original position qH to a new position qH + dH will change the force acting on body L. Thanks to our theoretical understanding of the system we also know that the position of body L will change from qL to qL + dL and we know how dL is related to dH given the masses MH and ML.
Sal.: getting to it in a minute. I understand you are familiar with the potential outcomes framework [11]? But here is a nice tutorial if you want [12]. We will apply it to our problem: finding out the effect of changes in qH on the force FL felt by body L. I am not saying what this force is because it does not really matter, but you can imagine it’s gravity. Considering that Josh may decide to move H to qH + dH we can write a general expression for the force FL as
FL = FL(qH) + (FL(qH + dH) − FL(qH)) D
where D = 0 if body H is in qH , D = 1 if body H is in qH + dH.
Sim.: I am not sure I understand what is going on.
Sal.: well, imagine that the force on L when H is in qH is 3 Newtons. So FL(qH) = 3. But if we move H to qH + dH the force becomes 2 Newtons, ok? Then FL(qH + dH) = 2. So FL = 3 + (2 – 3)D. But D is just a flag that is 1 if H is in qH + dH and 0 if H is in qH. So when H is in qH we get FL = 3 + (2 – 3)0 = 3. If we move H to qH + dH we get FL = 3 + (2 – 3)1 = 2.
Sim.: this seems just a complicated way to rewrite the obvious.
Sal.: yes, for now you are absolutely right; but bear with me. What about randomisation?
Amy: right, what about it? This setup seems entirely deterministic.
Sal.: remember our massless experimenter, Josh?
Amy: yes, even though it is not really clear to me why he is massless. Why is his mass zero?
Sal.: it’s an assumption that keeps the system simple. Having zero mass, Josh cannot move body H by just pushing on it and recoiling in the opposite direction. He has to lean on something else if he wants to move body H. The only other body he can lean on is body L, so he ends up moving body L too. If a guy that has no mass sounds too much like a ghost, you can imagine that we are in the limit where Josh is much lighter than H and L, so we can ignore his mass.
Amy: understood. So what has Josh to do with randomisation?
Sal.: Josh decides whether to leave body H in qH and just measure the force on body L, or to push body H to qH + dH before measuring the force. Since Josh is part of the system, his decision must depend on the state of the system. If we describe his internal state with some variables v1,v2, … we can average over all their possible values and write the expected value of the force difference measured by Josh as
E(FL | D = 1) − E(FL | D = 0) = E(FL(qH + dH )|D = 1) - E(FL(qH )|D = 0)
and then we can sum and subtract the term E(FL(qH )|D = 1), obtaining
E(FL(qH )|D = 1) + E(FL(qH + dH )|D = 1) − E(FL(qH )|D = 1) − E(FL(qH )|D = 0)
Sim.: sorry to interrupt, but what does each term mean?
Sal.: E(FL(qH + dH )|D = 1) is the expected value of the force measured by Josh when he placed body H in qH + dH. E(FL(qH )|D = 0) is the force he measures when he places body H in qH, and the counterfactual term E(FL(qH )|D = 1) represents the average force that would be felt by L if H were placed in qH in all those realisations of the system -corresponding to internal states of Josh that lead him to perform the experiment- in which H is actually placed in qH + dH. In the counterfactual, all the potential confounding variables have the values that they would have if H were placed in qH+dH but H is actually in qH. Can I go on?
Amy: sure.
Sal.: let me regroup the terms as follows:
[E(FL(qH + dH )|D = 1) − E(FL(qH)|D = 1)]TE + [E(FL(qH )|D = 1) − E(FL(qH )|D = 0)]SB
where we named the two parts TE (Treatment Effect) and SB (Selection Bias). In general Josh measures the sum of TE and SB; however TE is the direct effect on the measured force due to moving H from qH to qH + dH and presumably what we are really interested in measuring, while SB is an additional term due to the fact that every internal state of Josh that results in him choosing to place H in qH + dH may also result in conditions that indirectly affect the measured force FL. In general SB is not zero, and the experiment is not actually randomised. Let’s see this in more detail. First assume that the force FL depends on the distance between the two bodies L and H, which leads us to rewrite the effect measured by Josh as
[E(F (qL|D=1 − (qH + dH )))) − E(F (qL|D=1 − qH ))]TE+ [E(F (qL|D=1 − qH )) − E(F (qL|D=0 − qH ))]SB
and the TE term simplifies to
TE = E(F (qLD=1 − (qH + dH )) − F (qL|D=1 − qH ))
while the SB term becomes
SB = E(F (qL|D=1 − qH ) − F (qL|D=0 − qH ))
Now let us call qi|D=0 simply qi and write qi|D=1 as qi + di.
Using the fact that the system is isolated, so its center of mass is fixed in 0 in the appropriate reference frame (Fig. 2), we get
mH dH + mLdL = 0
In the following we will also assume dL and dH to be small, so we can expand to the first order, obtaining, for the TE term
TE = E(−F’|qL−qH dH)
and
SB = E(F’|qL−qH dL)
so
SB = TE dL/dH = TE mH/mL
so if the TE is not zero, neither is the selection bias. The actual measurement is the sum of TE and SB:
SB + TE = (1 + mH/mL)TE
So there is an unavoidable bias. This is because moving particle H by dH away from the center of mass has two effects on the force felt by particle L: it increases the distance between the two particles directly by dH, reducing the force proportionally to F’dH , but it also moves particle L away from the center of mass by mH dH /mL, so that the center of mass does not move. Since the system is isolated, the massless experimenter is not free to just move H: he must push on L to move H, causing L to move as well. The term mH dH /mL is a selection bias because every time Josh brings particle H in qH + dH at time t he must also bring particle L in qL – (mH /mL)dH. So the intended effect of our experiment (moving particle H by dH ) has an additional unintended but inevitable consequence, which cannot be disentangled from the direct effect of our manipulation.
Sim.: this is a very contrived example, and the problem would disappear if we considered Josh’s intervention to affect the distance between L and H rather than the absolute coordinate qH.
Sal.: I admit it. But it shows that you cannot take for granted that you can run randomised experiments in any system. What are the minimal requirement for a mechanical system to allow for randomised experiments to exist?
Amy: hard to say. You are asking whether an experimenter E who is fully embedded within some closed system U -whose mechanics is assumed deterministic and fully known to us- can run a randomised experiment when all the variables (assignment to treatment, treatment, outcome) are required to be state variables of the system or functions thereof?
Sal.: Yes, and keep in mind that E has no random number generator available [13] and –clearly- no `free will’, whatever that is supposed to be.
Amy: Alternatively, one could consider an observer F external to U that fully knows the evolution of all state variables of U with time. Would they be able to determine whether there is a causal relation -in the statistical sense- between a variable in U and another?
Sal.: Since F cannot manipulate U in any way, due to U being closed and F being external to U, the latter formulation is equivalent to asking whether natural experiments can occur in U. Natural experiments in the social sciences are often conceptualised in terms of instrumental variables [14]. When an outcome variable Y depends on treatment X but the relation is confounded by some other variable W, an instrumental variable is a variable Z that affects Y only through X. Random assignment to treatment is an extreme example, where the output of a random number generator has an effect on the outcome Y only by determining who receives treatment X. Instrumental variables encountered in the wild are unlikely to be as good as deliberate randomisation, but are often leveraged anyway for causal inference in empirical work based on observational data. Thus a way to restate and generalise our question which makes its importance clear for the practitioner is: can instrumental variables arise in a mechanical system, and under which conditions? Are there general guarantees that the systems typically studied with these methods are of this kind?
Amy: did you try to answer these questions?
Sal.: not really, because I cannot yet decide at which level of generality it is convenient to work. Should I pick a general dynamical system? A Hamiltonian one?
Amy: maybe you could start with a system of N classical, non-interacting particles, all moving inertially. Do you see any instrumental variables there?
Sal.: under these assumptions the position of the i-th particle evolves in time as
xi(t) = vit + x0i
so every variable is perfectly correlated to every other. There are no instrumental variables. We won’t be able to test whether xi causes xj for any i, j.
Amy: interestingly, it is often stated that forces cause motion or, more precisely, changes in motion. For instance Max Jammer [15] writes that the change of motion is an effect and the impressed force its cause while referring to Newton’s notion of vis impressa. So force-free, inertial motion is precisely motion without a cause. Or natural motion if you want.
Sal.: Where do we go from here? Certainly this can be extended to all sorts of homothetic motion including Hubble flow and the evolution of central configurations in the N-body problem [16], but what comes next? Mmh…
Amy: sounds like the starting point for a new field of study.
Sim.: or a half baked idea…
Sal.: I will just put it up on my blog and see what happens.
[1] https://www.billnye.com accessed on Nov. 19, 2022
[2] Cox, David Roxbee, and Nancy Reid. The theory of the design of experiments. Chapman and Hall/CRC, 2000
[3] Rohrer, Julia M. "Thinking clearly about correlations and causation: Graphical causal models for observational data." Advances in methods and practices in psychological science 1.1 (2018): 27-42
[4] Holland, Paul W. "Statistics and causal inference." Journal of the American statistical Association 81.396 (1986): 945-960
[5] Textor, Johannes, Juliane Hardt, and Sven Knüppel. "DAGitty: a graphical tool for analyzing causal diagrams." Epidemiology 22.5 (2011): 745.
[6] Pearl, Judea. Causality. Cambridge university press, 2009.
[7] McCormmach, Russell. "Mr. Cavendish weighs the world." Proceedings of the American Philosophical Society 142.3 (1998): 355-366.
[8] Fischbach, Ephraim, and Carrick L. Talmadge. The search for non-Newtonian gravity. Springer Science & Business Media, 1998.
[9] Newell, Allen. "You can't play 20 questions with nature and win: Projective comments on the papers of this symposium." (1973).
[10] Russo, Lucio. The forgotten revolution: how science was born in 300 BC and why it had to be reborn. Springer Science & Business Media, 2003.
[11] Donald B Rubin (2005) Causal Inference Using Potential Outcomes, Journal of the American Statistical Association,100:469, 322 331
[12] https://www.causalconversations.com/post/po-introduction
[13] A random number generator may in principle arise naturally in a given system, but it is reasonable to believe that certain conditions must be satisfied for this to happen in a deterministic system. For instance one would expect a chaotic system to be more suitable than an integrable one. Iterating simple deterministic functions such as the sawtooth map (see e.g. Dawes, Jonathan, 2008 https://people.bath.ac.uk/jhpd20/lecturenotes/chaos_chapter.pdf) effectively turns the uncertainty inherent in a system’s initial conditions into an effectively random sequence. Note the connection with regression discontinuity a few posts back.
[14] Angrist, Joshua D., and Jörn-Steffen Pischke. Mostly harmless econometrics: An empiricist's companion. Princeton university press, 2009
[15] Jammer, Max. Concepts of force: A study in the foundations of dynamics. Courier Corporation, 1999; chapter 7
[16] http://www.scholarpedia.org/article/Central_configurations#Homothetic_Solutions
A heartfelt thank to the gardeners of Seeds Of Science (https://www.theseedsofscience.org) for reviewing a draft of this post and suggesting improvements. This was originally submitted as a paper for publication in that journal, but after a round of revision it was rejected. Given the highly speculative yet still somewhat technical nature of the material I will not bother submitting it elsewhere, so I just put it up here with minor changes.
Hi Mario,
what you wrote made me think at something that happened in condensed-matter theory at the end of the '90s / beginning ot the 2000s. People were studying the fractional quantum Hall effect, a terribly complicated problem, and a standard technique for doing it is by proposing a wavefunction that is expected to describe the properties of the electron gas that are measured in experiments.
In particular, people were very interested in how these electron gases react to the presence of impurities. Impurities appear in these wavefunctions via parameters indicating their positions, that one can change at will, and there is a rather established interest in placing two impurities and understanding the effect of one onto the other. It's the starting point of a fascinating topic dealing with fractional anyonic statistics (that we will leave for another comment). In any case, our understanding of the fractional quantum Hall effect is non negligible, and in several cases we can anticipate what this mutual effect of the two impurities is. It turns out that for one specific wavefunction (specifically, a Laughlin wavefunction with two quasielectrons) people computed numerically the mutual effect using the wavefunction and got results that were completely incompatible with the general theoretical expectations. It took them several years to understand what was going on: the wavefunction had as input parameters the position of the impurities but it was realizing them at different positions (a crazy thing, that I still don't truly understand). Once people looked at the wavefunction by plotting its density profile, the riddle was easily solved. The impurities were not placed where people thought, and the obtained results were in fact compatible with the general theory - with the correct impurity positions.
The funny thing, that reconnect with your dialogue, is that the check based on the plot had been performed int he case of one impurity: in that case, the impurity is formed where you expect it to be. It's when you add the second that the positions get messed up. Funny no? It seems a bit the story of your dialogue, where a wrong knowledge of the position of the second mass gives a wrong prediction. And it reconnect nicely with the post on Persico: can we understand thing if we don't plot them? I wonder whether a machine-learning algorithm would get the mutual effect right.
In any case, there is a nice side in this story. People published this result that was not understood, and they wrote it clearly. They did not hide it, they did not change it. A good scientific practice.