


Bringing (more) causality to astronomy
What I am trying to do in the near future

It was April 2023 when I started thinking seriously about applying causal discovery to astronomy. I had been reading about causality -mostly Pearl's book and a few of his articles- back in summer 2020. Still it only was during a meeting at CCA in NY that the ideas buzzing around in my head finally congealed into a clear research project.
I started by just throwing the PC algorithm at a suitable tabular dataset, which ended up being about galaxies and supermassive black holes mostly because of the availability of a subject matter expert, Ben, who curated the dataset. As it turns out, that was a great choice from the scientific point of view, since the coevolution of supermassive black holes and their host galaxies is a long standing chicken-and-egg problem that causal discovery methods could indeed contribute to solving. This led to my 2023 poster at the ML for physical sciences workshop at NeurIPS in New Orleans.
Unfortunately, though, the PC algorithm (and its friend the FCI algorithm, and all constraint-based causal discovery algorithms really) relies on running a large number of conditional independence tests, which explodes with the number of variables involved. It then becomes virtually certain that at least one test will be wrong, just by chance, and this can have deep repercussions on the whole causal structure we end up learning. Furthermore, the result is a point estimate: *this one* (modulo Markov equivalence) is the best DAG, and that's it. So if subject matter knowledge suggests that the DAG is actually wrong, there is no second-best one to look at.
It was only when Zehao came to visit me in Montréal that we switched to score-based causal discovery, thanks first to Yashar's passionate advocacy of Bayesian methods and then to input from Bengio's group (basically Tristan). The curse of dimensionality that affected constraint-based methods went out of the door, but it came back from the window to haunt our score-based method: sampling from the posterior distribution on all directed acyclic graphs becomes increasingly difficult as the number of variables increases and the number of graphs grows super-exponentially. That's where GFlowNets came to the rescue, even though in the end we settled on using just seven variables, making a full exact posterior calculation tractable.
Another important step forward came from realizing that the behavior of elliptical, lenticular, and spiral galaxies was not the same, so we should not throw all the data in the same bucket. It turns out that in spiral galaxies it is the black hole's mass that causes the other properties of the galaxy, but in lenticulars and especially in ellipticals it is the other way around. At this point it was clear that we had enough material to write a good paper and we went for it.
Both Nature and Science ended up desk-rejecting it though. In case you are not familiar with the term, this does not mean that the journal editor is flipping over his desk in anger because of how bad the paper is. It just means that the editor's decision is not to send the paper to the referee(s) and to reject it without submitting it to peer review first. This is pretty common in big name journals like Nature and Science, who need to show off their low acceptance rate. At least desk rejection is fast and one usually ends up taking a deep breath and moving on.
So after reformatting the whole thing we sent it to ApJ, which ended up accepting it pretty quickly. And here it is.
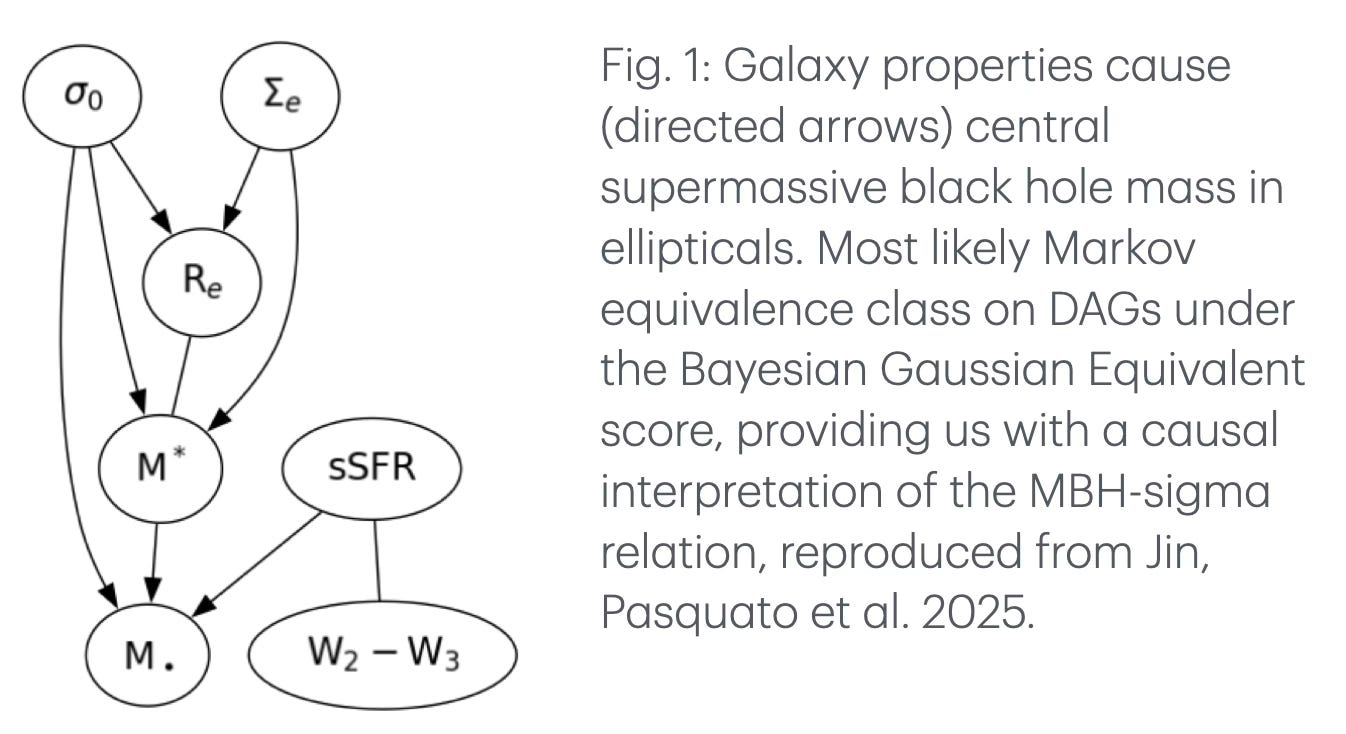
But what should be the next step? On the one hand the work we did is honestly quite impressive, being the first application of causal discovery to astronomy and all. On the other hand, it really just is the tip of the iceberg: we can do so much more than this!
The first direction we could be working towards is perhaps the most obvious: just pick the low hanging fruit and start applying causal discovery systematically to all tabular datasets of astronomical quantities we can find: globular and open star clusters in the Milky Way, star forming regions, planetary nebulae, exoplanets, galaxy clusters, you name it. While this does not sound very exciting, it is likely to yield at least some new results. Also, individual datasets are likely to present specific challenges, similarly to what happened with the supermassive black hole host galaxies, where spirals and ellipticals differed. So there is probably a lot to learn even from this simple exercise.
Still, it's clear there is plenty of cooler stuff we could be trying. For instance, why stick to tabular datasets? There's images, spectra, time series and even textual annotations from volunteers in citizen science projects. There is point cloud data, such as the positions and velocities or the colors and magnitudes of stars in a given field. The main issue with these is that you can't imagine a single pixel in an image causing, say, star formation rate or a single pixel in a spectrum causing redshift. We need to learn suitable representations -complex features obtained by combining pixels or similar low level information into meaningful units- so that these can be placed in causal relation with physical quantities. Representation learning is well established by now, so we should at least be able to apply some out-of-the-box methods, such as contrastive learning, and get features we can apply causal discovery to. Perhaps more ambitiously, we could attempt genuine causal representation learning. This seems like a big project even if limited to a corner of astronomy, and in fact I am trying to obtain funding to work on this.
A third avenue of research could start from the theoretical issues faced when applying causal discovery to real data: cycles, lack of causal sufficiency, whether CD is applicable to equilibrium systems, and of course robustness to outliers. Another related question is whether we can rely on a learned causal order to reconstruct the temporal order over snapshots of cosmological simulations, or at the very least show that time is one-dimensional by arranging all snapshots along a fork, if not in a chain.
There really is plenty of work to do!